In this article I’ll run through how I used Rust and pyo3 to implement a fast BPE tokenizer (4x faster than tokenizers and as fast as tiktoken) which you can install from PyPI today!
All the code mentioned in this post can be found on github at this repo 🪙.
I’m mainly going to write about an efficient way I discovered to quickly encode and decode sequences using a pretrained tokenizer instead of an in-depth review of byte-pair encoding. For that check out any one of these links:
The naive approach - O(mn)
Suppose you’ve already trained a tokenizer, i.e. you have a wrapper around a hashmap that lets you map a sequence of bytes to unique tokens. What’s the fastest way to use this lookup table to encode and decode your data?
The first idea that comes to mind might be to loop over all the possible token merges in the order we learned them and replace any matches we find along the way. For example, if your tokenizer has the following token mapping rules:
{(97, 97): 128, (128,97): 129, (129, 98): 130}Then the encoding for “aaabcaaab” (or [97,97,97,98,99,97,97,97,98] as a byte array) would go sequentially like:
- [97,97,97,98,99,97,97,97,98] -> [128,97,98,99,128,97,98]
- [128,97,98,99,128,97,98] -> [129,98,99,129,98]
- [129,98,99,129,98] -> [130,99,130]
In Rust that procedure can be written as below:
use std::collections::HashMap;
type Rank = u32;
fn _byte_pair_merge(pieces: &mut Vec<Rank>, pair: (Rank, Rank), replace: Rank) {
let mut i = 0;
while i < pieces.len() - 1 {
if (pieces[i], pieces[i + 1]) == pair {
pieces[i] = replace;
pieces.remove(i + 1);
}
i += 1;
}
}
fn encode(text: &str, map: &HashMap<(Rank,Rank), Rank>) -> Vec<Rank>{
let mut pieces: Vec<Rank> = text.as_bytes()
.iter()
.map(|&x| x as Rank)
.collect();
//reverse (k,v) to (v,k)
let reverse_map: HashMap<Rank, (Rank, Rank)> = map.iter()
.map(|(&p, &r)| (r, p))
.collect();
//O(m*n)
//assume first token has index 128 since we're encoding for ascii
(128..=reverse_map.len() + 128).rev().for_each(|i| {
let &pair = reverse_map.get(&(i as Rank)).unwrap();
_byte_pair_merge(&mut pieces, pair, i as Rank);
});
pieces
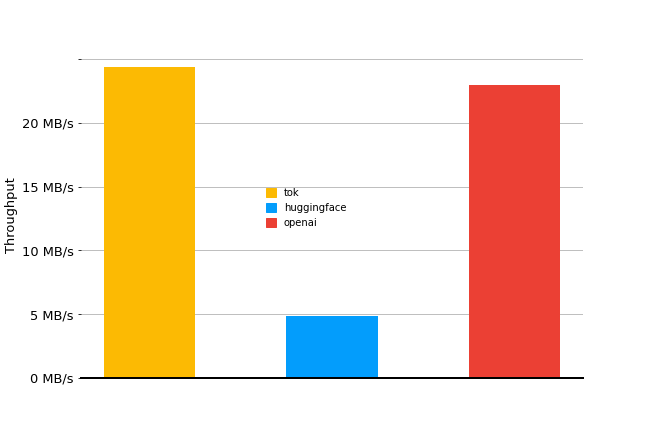
}For a vocabulary size of 50257, the token throughput with this approach for a 2.5MB subset of the wikitext dataset is somewhere in the neighborhood of 0.09MB/s.
This approach definitely gets the job done but it’s incredibly inefficient! Indeed, this solution has a time complexity of , where is the vocab size and is the length of the text you want to encode. As the vocabulary size and/or length of the text increase we get significant slowdowns.
A more efficient solution - O(m log(n))
The approach I ended up stumbling across after around 6 hours of refactoring is closer to . It relies on the fact that we don’t need to loop over every entry in the hashmap when it’s sufficient to notice that we can apply merges in a way which respects the order the tokenizer learned them in. This lets us apply multiple different token merges in a single pass instead of only searching for a single pattern each time. We can also detect early on if no more token merging is possible and break out of the function.
//lib.rs
fn encode(text: &str, map: Map<(Rank,Rank), Rank>) -> Vec<Rank> {
let mut pieces: Vec<Rank> = text.as_bytes().iter().map(|&x| x as Rank).collect();
loop {
let mut merges = Vec::new();
for i in 0..pieces.len() - 1 {
if let Some(&rank) = map.get(&(pieces[i], pieces[i + 1])) {
merges.push((i, rank));
}
}
//early stopping
if merges.is_empty() {
break;
}
// apply merges and swap in tokens from reverse
let mut i = merges.len() - 1;
while i > 0 {
let x = &mut merges[i - 1..=i];
let l = x[0];
let r = x[1];
if r.0 - l.0 > 1 && r.1 != Rank::MAX {
pieces[r.0] = r.1;
pieces.remove(r.0 + 1);
} else if r.1 < l.1 {
pieces[r.0] = r.1;
pieces.remove(r.0 + 1);
x[0].1 = Rank::MAX;
i -= 1;
}
//avoid overflow on usize 0-1
if i == 0 {
break;
}
i -= 1;
}
if merges.len() == 1 || merges[0].1 < merges[1].1 {
pieces[merges[0].0] = merges[0].1;
pieces.remove(merges[0].0 + 1);
}
}
pieces
}On the same wikitext split our throughput using this encoding algorithm jumps to 24.35MB/s. That’s over a 100x improvement with respect to where we started from.
I took a lot of inspiration from official openai implementation in their repo tiktoken but handled the merging aspect quite differently by leveraging the fact that we could store the prospective merges in a stack instead of finding the single-best merge at each iteration.
PyO3 and the toktokenizer package
To expose the Rust code in Python I made use of pyo3 and maturin. Getting started with these libraries is incredibly easy and just requires adding a few pyo3 attributes to your existing rust code. What’s also nice is that maturin automatically adds a CI github workflow to your project which makes distributing your python package infinitely easier. By default the workflow listens for new tag pushes to the main branch and builds the wheels for all the major platforms.
I encourage you to check out a few official examples and the pyo3 docs, overall though its a pretty frictionless experience.
Using maturin I published toktokenizer - a lightweight python package for BPE tokenizers - to PyPI. The only class the library exposes is BPETokenizer. The class itself is pretty minimalistic, with all major methods being showed below:
# demo.py
from toktokenizer import BPETokenizer
bpe = tok.BPETokenizer()
# train a byte-pair tokenizer on some corpus
train_corpus = "this is some training data"
vocab_size = 8
bpe.train(train_corpus, vocab_size)
# save tokenizer state
bpe.save_encoder("8word.json")
# load tokenizer from dumped file
bpe.load_encoder("8word.json")
# encode and decode
input_ids = bpe.encode("some data")
decoded = bpe.decode(input_ids)To get started with toktokenizer today you can install it with pip as follows:
pip install toktokenizerI’m looking forward to using this library moving forwards as I build up various components of modern NLP models from scratch!